Network Topology v6 für Zabbix — Update v4.19.0
Im April hatte ich Network Topology vorgestellt — das native Zabbix-Modul, das aus den vorhandenen Daten eine moderne, interaktive Netzwerk-Map rendert. Damals waren es drei Ansichten und ein Cytoscape-Graph mit Severity-Ringen.
Seitdem hat sich einiges getan. Genug, dass aus v5 ein v6 geworden ist und der Funktionsumfang sich an den Stellen, an denen man im Alltag wirklich klickt, deutlich verbessert hat. Hier die wichtigsten Neuerungen.
Aus drei Ansichten werden vier
Die hierarchische Ansicht ist als eigener Tab verschwunden — sie lebt jetzt als Sub-Layout innerhalb der technischen Ansicht weiter (per Toolbar-Toggle, neben Force/Raster/Konzentrisch). Dafür gibt es zwei komplett neue Tabs: Tabelle und Geo.
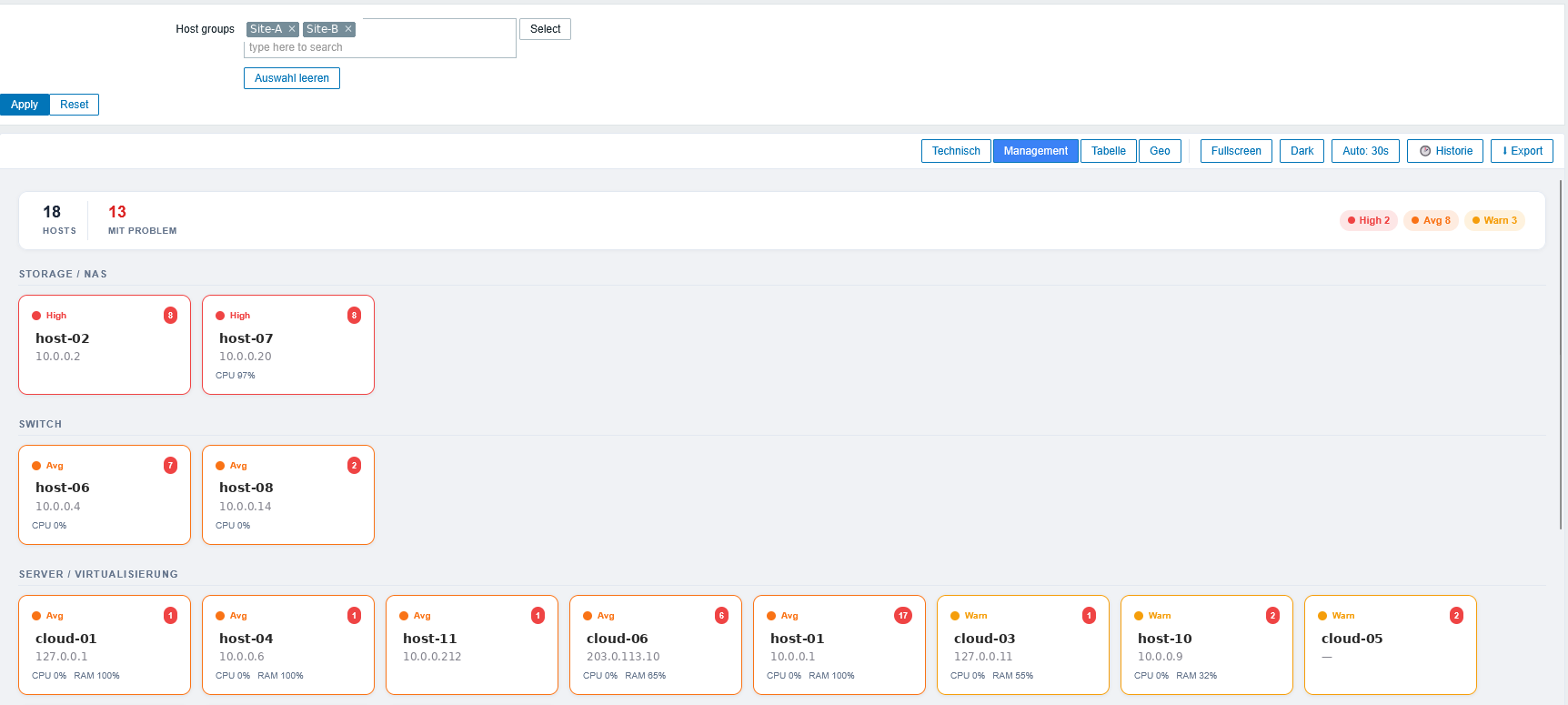
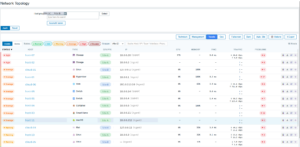 Tabelle: Hostliste und Items-Pivot
Tabelle: Hostliste und Items-Pivot
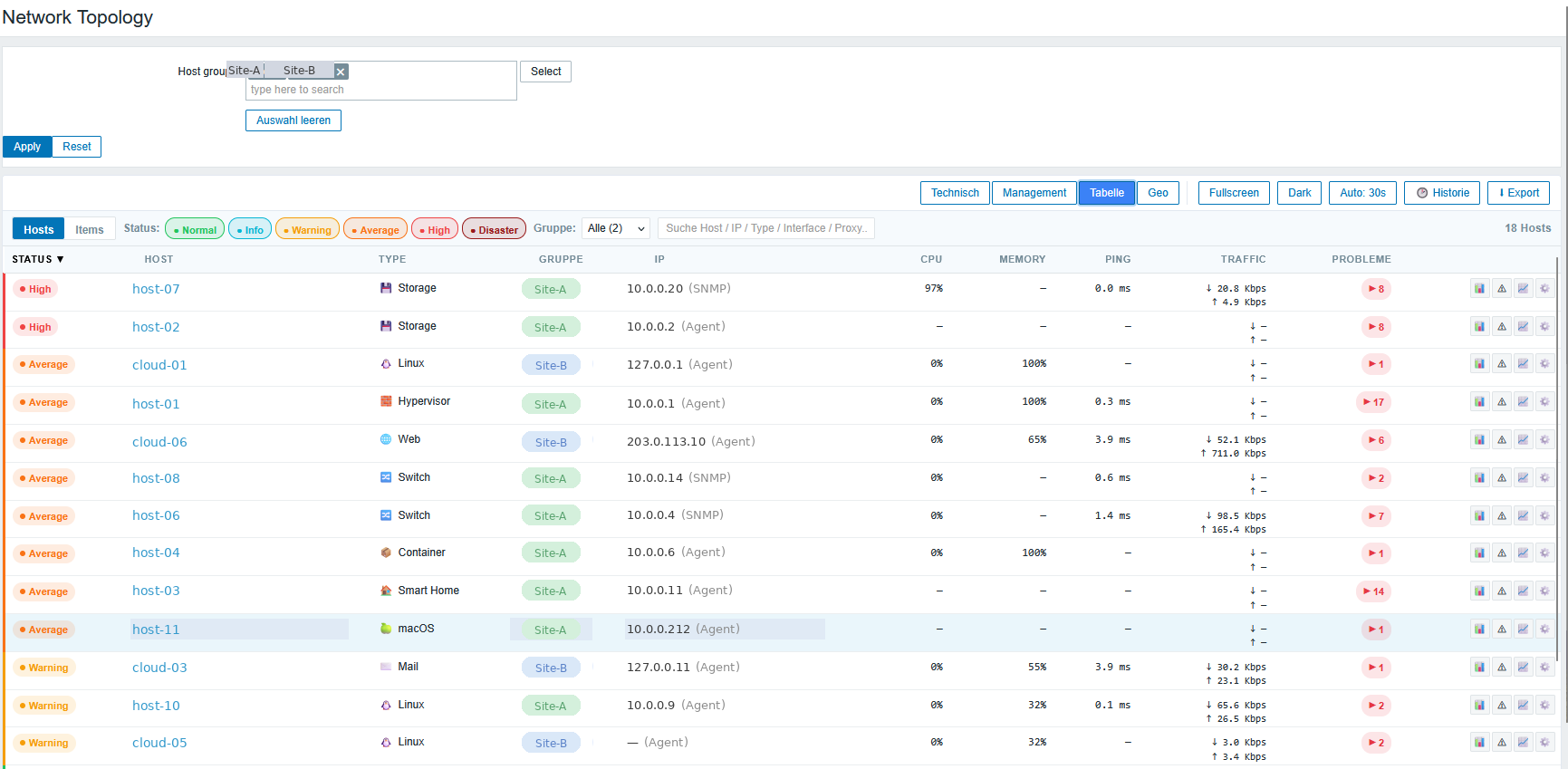
Der Tabellen-Tab ist die nüchterne Sicht für den Alltag — eine Hostliste im Nagios-/Icinga-Style. Status, Type, IP, CPU, Memory, Ping, Traffic, Probleme — alles sortierbar, mit Severity-Pille pro Zeile, Volltext-Suche über Hostname/IP/Type/Interface/Proxy und einem Severity-Filter (Disaster/High/Avg/Warn/Info/Normal als Pillen togglebar). Klingt unspektakulär, ist aber der Tab, in dem ich inzwischen am häufigsten lande, wenn ich wirklich nur schnell wissen will: wer ist gerade dran.
Neu in v4.19.0: der Probleme-Counter pro Host ist aufklappbar. Klick darauf öffnet eine Detail-Zeile mit den einzelnen Problemen — Severity-Punkt, Name, Acked-Häkchen, Alter. Das Backend liefert pro Host bis zu 20 Probleme, sortiert nach Severity desc und Clock desc. Spart das ständige Wechseln zur Zabbix-Problems-Seite.
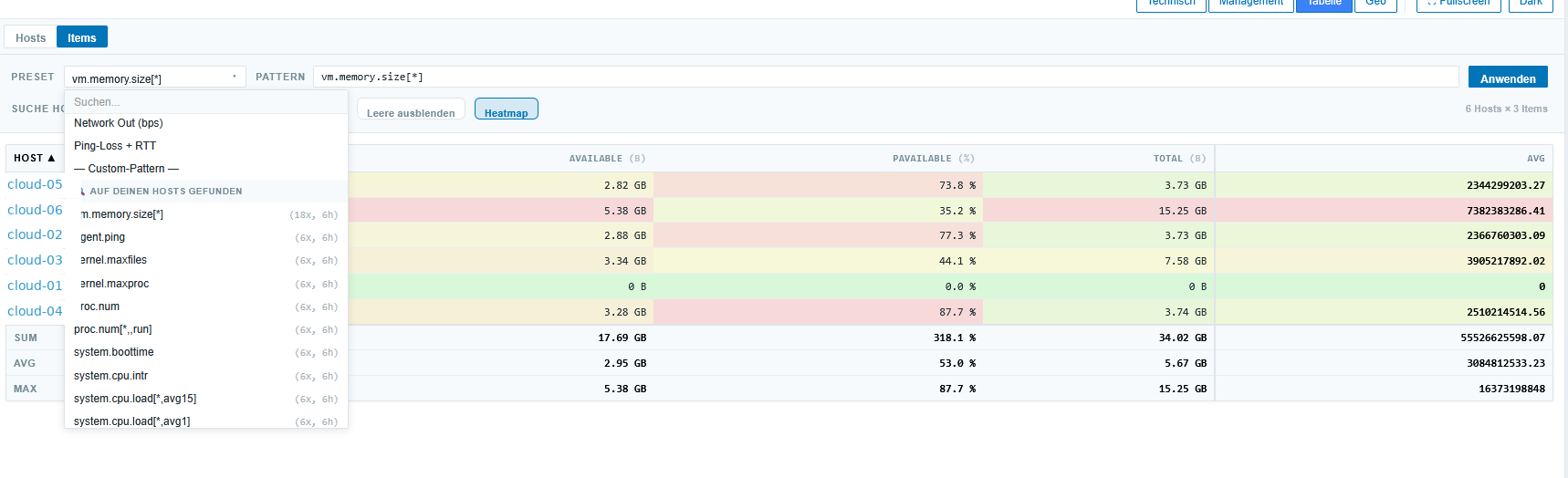
Daneben gibt es einen zweiten Modus: Items-Pivot. Man gibt ein Item-Key-Pattern ein (z.B. vfs.fs.size[*,pused]) und bekommt eine Pivot-Tabelle Hosts × Items als Heatmap. Alle Disk-Auslastungen einer Hostgroup auf einen Blick, oder alle vm.memory.size, oder alle agent.ping — egal, solange das Pattern matched. Die Zellen werden farblich nach Wert eingefärbt (grün/gelb/rot), zusätzlich gibt es Sum/Avg/Max-Zeilen am Fuß.
Es gibt ein paar fertige Presets (Memory, CPU-Util, Network In/Out, Ping-Loss + RTT) plus eine Auto-Discovery, die die häufigsten Items in der aktuellen Hostgroup-Auswahl vorschlägt — inklusive Anzahl der matchenden Hosts und letzter Aktualisierung. Aus den Vorschlägen lassen sich Custom-Patterns ableiten, die dann auch mit Wildcards (*) und Komma-Argumenten funktionieren.
Geo-Ansicht für verteilte Standorte
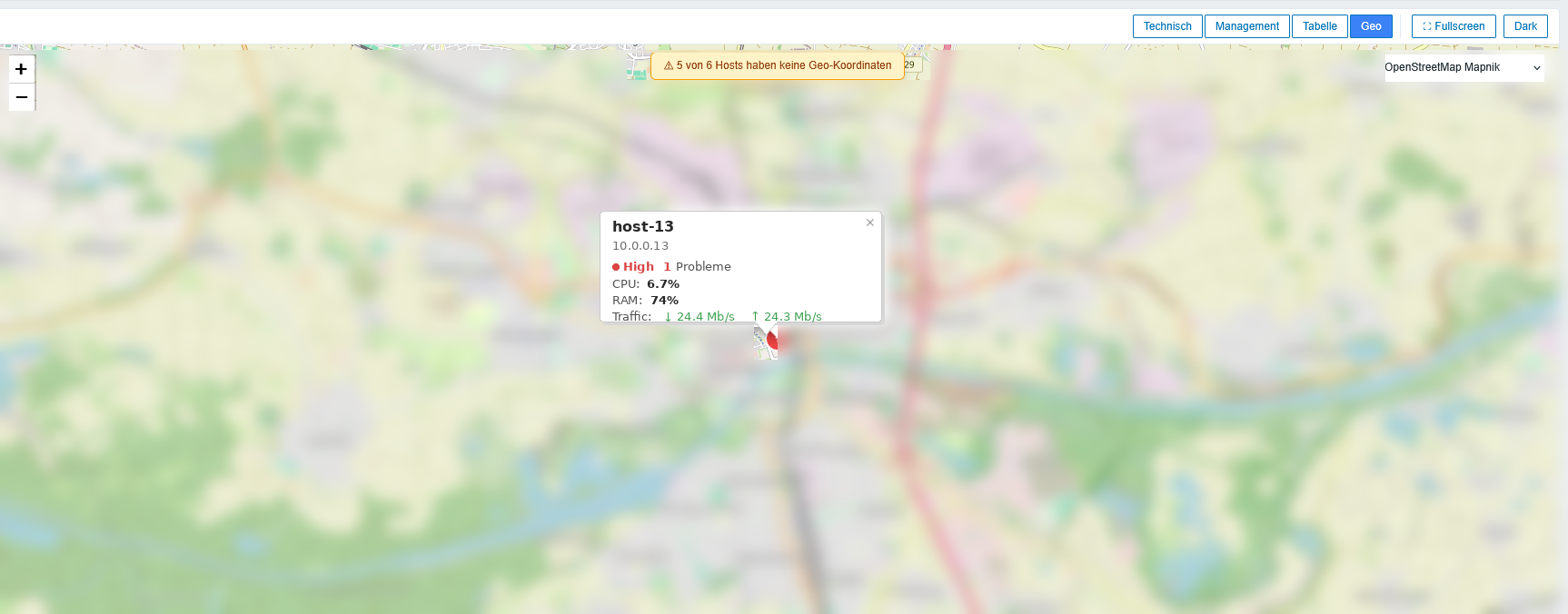 Wer Hosts mit GPS-Koordinaten in den Inventory-Feldern (
Wer Hosts mit GPS-Koordinaten in den Inventory-Feldern (location_lat + location_lon) hat, bekommt sie jetzt auf einer Leaflet-Karte. Tile-Layer ist OpenStreetMap Mapnik per Default, lässt sich aber umschalten. Marker zeigen die Severity-Farbe, Klick öffnet ein kompaktes Popup mit Hostname, IP, CPU, RAM und Live-Traffic.
Für eine Single-Server-Umgebung ist das uninteressant. Aber wenn man Außenstandorte oder ein verteiltes Setup über mehrere Städte hat, ist es wirklich praktisch — gerade weil ein orange-roter Pin auf der Landkarte sehr viel mehr Wirkung hat als die gleiche Information in einer Tabellenzeile.
Cluster-Layouts statt Spaghetti
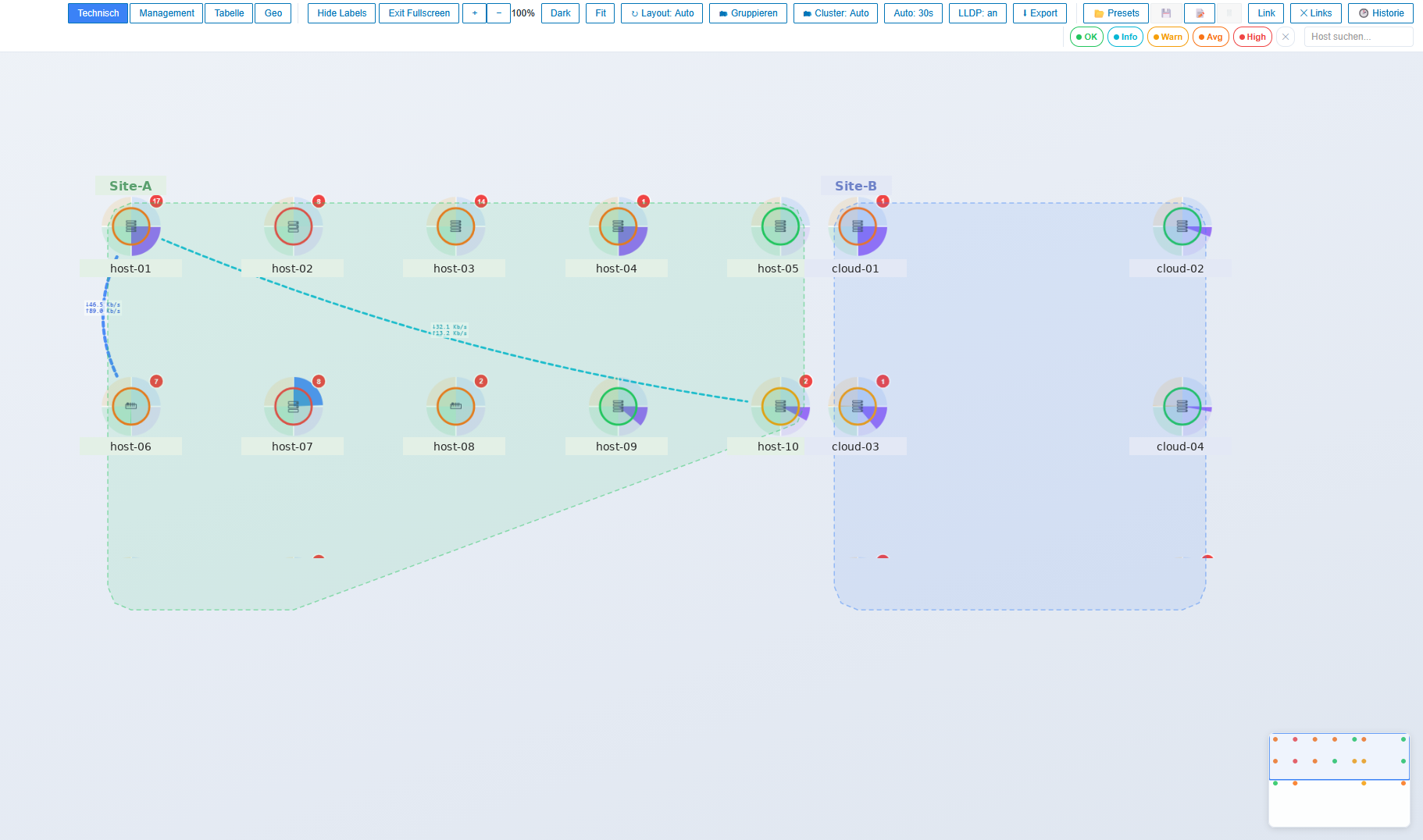 Bei Multi-Group-Auswahl (z.B. „intern“ und „extern“ gleichzeitig) verlief das Force-Layout in v5 schnell zu einer großen Knäuel. Seit v4.18 läuft das adaptiv:
Bei Multi-Group-Auswahl (z.B. „intern“ und „extern“ gleichzeitig) verlief das Force-Layout in v5 schnell zu einer großen Knäuel. Seit v4.18 läuft das adaptiv:
- 2–3 Hostgroups → vertikale Spalten
- 4+ Hostgroups → horizontale Reihen
- Auto / Spalten / Reihen / Aus per Toolbar-Toggle
Jede Gruppe bekommt ihre eigene Box mit Convex-Hull-Lasso (gestrichelte Linie + Label), und der Sichtgap zwischen den Hüllen ist großzügig genug, dass man die Gruppen sofort als getrennte Einheiten wahrnimmt. Innerhalb der Hülle läuft das gewählte Layout — Force, Raster, Baum, Konzentrisch — jetzt per Cluster statt global. Das war eine der Änderungen, die im Alltag den größten Unterschied gemacht hat.
Die Cluster-Modi werden im localStorage gemerkt, ebenso die Layout-Presets, die man jetzt als benannte Snapshots speichern und laden kann.
History-Mode mit Slider
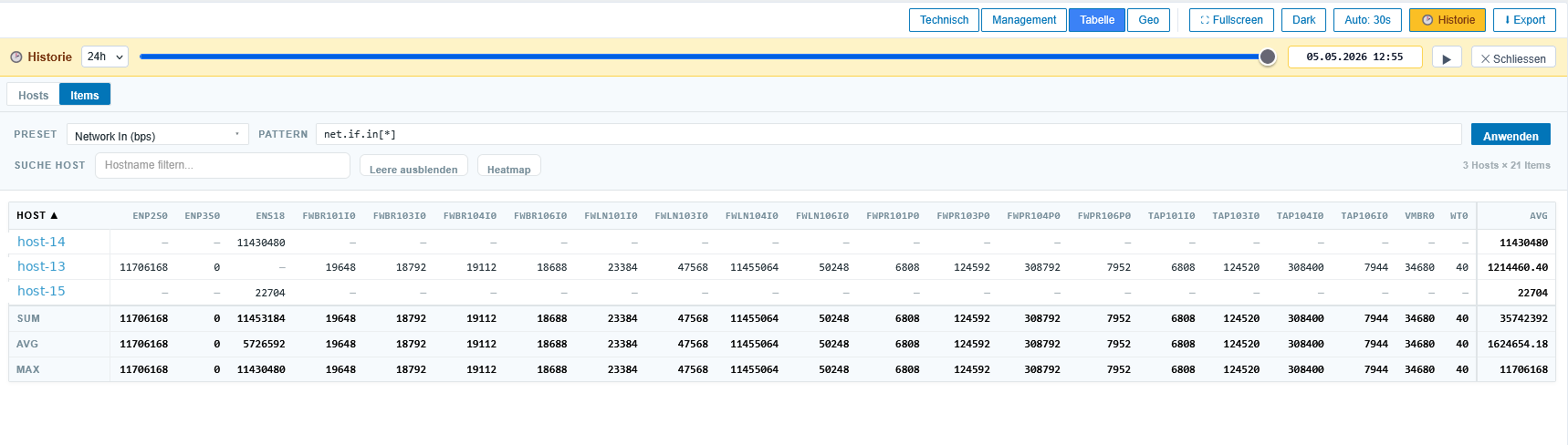 Der zweite Killer im Alltag: ein Toggle in der Toolbar öffnet eine Zeitleiste über 1h / 24h / 7 Tage, und der Trigger-Status wird zum gewählten Zeitpunkt zurückgespielt. Die Map zeigt also nicht mehr den Live-Stand, sondern den Stand von vor zwei Stunden, von gestern Abend, von letztem Mittwoch.
Der zweite Killer im Alltag: ein Toggle in der Toolbar öffnet eine Zeitleiste über 1h / 24h / 7 Tage, und der Trigger-Status wird zum gewählten Zeitpunkt zurückgespielt. Die Map zeigt also nicht mehr den Live-Stand, sondern den Stand von vor zwei Stunden, von gestern Abend, von letztem Mittwoch.
„Wie sah das aus, als der Kunde um 14:23 angerufen hat?“ — Slider auf 14:23 schieben, fertig. Aus Sicherheitsgründen ist die Range auf 7 Tage und maximal 50 000 Events begrenzt; CPU, Memory und Traffic bleiben Live, weil History für jeden Item-Wert eines mittelgroßen Setups schnell richtig viele Datenbankabfragen werden.
Custom-Tags am Host
Anstelle einer eigenen Konfigurations-UI nutzt das Modul Zabbix-Tags am Host. Wer das Verhalten der Map pro Host anpassen will, klebt einfach Tags ran:
nt:icon=switch— überschreibt das automatisch erkannte Device-Iconnt:label=Core-Switch DC1— alternativer Anzeigename in der Mapnt:note=Reboot 2026-06-12 geplant— kleiner Notiz-Sticker am Knotennt:link=Wiki|https://wiki.example/host/123— Custom-Link im Kontextmenü (mehrfach möglich)nt:show=system.uptime— zusätzlicher Item-Wert im Tooltip
Das Schöne daran: die Visualisierungs-Konfiguration bleibt am Host, wo sie hingehört. Keine zweite Datenbank, keine Hosts-die-im-UI-existieren-aber-im-Modul-anders-heißen, kein Sync-Problem.
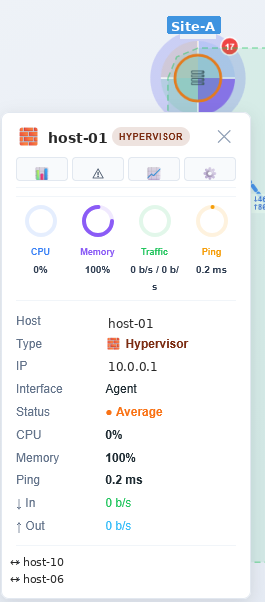
Detail-Panel statt Modaldialog
Klick auf einen Knoten oder eine Tabellenzeile öffnet jetzt eine Seitenleiste rechts statt eines Modals — Severity, CPU, Memory, Ping, Traffic, Geräte-Typ mit Custom-Indikator wenn ein nt:icon-Tag das Auto-Detect überschreibt, Interface (Agent/SNMP/IPMI/JMX) plus Proxy-Info, und vier Action-Buttons direkt zu Latest Data, Probleme, Graphs und Bearbeiten. Die restliche Map bleibt sichtbar.
Auch hier eine Kleinigkeit, die einen größeren Unterschied macht als gedacht: ein Modal reißt einen aus dem Kontext, eine Seitenleiste lässt einen drin.
Sicherheit nicht nachträglich
Bei der Gelegenheit: alle Actions prüfen USER_TYPE_ZABBIX_USER, Permission-Filter laufen über API::HostGroup()->get() statt Frontend-Trust, jede Ausgabe geht durch eine zentrale esc()-Funktion, DB-Zugriffe nutzen (int)-Cast oder dbConditionInt(). Item-Patterns brauchen mindestens drei Non-Wildcard-Zeichen (sonst matched man versehentlich Tausende Items), History-Calls sind auf 7 Tage und 50 000 Events begrenzt, Spark-History auf 50 Hostids pro Call. nt:link-URLs sind auf 2048 Zeichen, http/https only und ohne CRLF beschränkt.
Race-Conditions in async Fetches (History-Slider, Items-Pivot) werden über Sequence-Counter abgefangen — ein Detail, das man erst dann zu schätzen lernt, wenn man mal Daten aus der falschen Antwort gerendert hat.
Stand der Dinge
Aktuelle Version ist 4.19.0, mit aufklappbaren Probleme-Listen in der Tabelle, Stats-Header im Management-Tab und einem Cache-Buster, der sich aus dem max. mtime der Hauptdateien ableitet (kleines Detail, große Wirkung beim Deployment — keine alten JS-Versionen mehr im Browser-Cache).